Как работают вычислительные машины
С чисто формальной точки зрения современные вычислительные машины - это просто машины Тьюринга, которые работают с алфавитом, состоящим из двух символов ("0" и "1"), и способны принимать астрономическое число состояний. Аналогично, однако, можно было бы сказать, что поскольку и велосипед, и современный пассажирский самолет - транспортные средства для перевозки людей, они идентичны с формальной точки зрения. Современные вычислительные машины отличаются от рассмотренных машин Тьюринга способами построения и управления ими.
Многим известно, что вычислительная машина может сравнивать фамилии, напечатанные на кредитных карточках, с фамилиями, зафиксированными каким-то образом в памяти вычислительной машины. Многие до сих пор считают, что вычислительные машины - по существу, машины, способные в большом объеме выполнять арифметические расчеты, т. е. что они являются просто автоматическими настольными счетными машинами, обладающими очень большим быстродействием. Хотя это убеждение оправдано с чисто формальной точки зрения, значительно целесообразнее признать, что вычислительная машина - это в сущности устройство для обработки символов. Среди символов, которыми вычислительная машина может оперировать, имеются такие, которые люди, а в определенном смысле даже вычислительные машины интерпретируют как числа. До сих пор значительная часть машинного времени большинства вычислительных машин посвящалась заданиям нечислового характера.
Для объяснения только что сказанного необходимо обратиться к собственно символам и их интерпретации. При этом следует также объяснить, каким образом символы могут быть представлены, особенно "внутри" вычислительных машин.
Давайте, по крайней мере, здесь ограничимся символами, используемыми для создания текста. К ним относятся прописные и строчные буквы английского алфавита, знаки препинания и специальные символы типа используемых в математике, например скобки и знаки суммирования и равенства. Пробел (или интервал) также рассматривается как отдельный символ.
В противном случае было бы нелегко писать предложения, составленные из отдельных слов. Книги, состоящие из верениц одних этих символов, могут заставлять нас смеяться и плакать, могут поведать нам историю философии, отдельного человека или народа и могут научить нас самым разнообразным вещам, в том числе и математике. В частности, они могут научить нас строить алгоритмы, т. е. эффективные процедуры, а также снабдить нас наборами правил, образующими алгоритмы. Таково, хотя и не формальное, представление о том, какая информация нас интересует. Следует согласиться, что символы, которые мы имеем в виду, способны быть носителями информации. Каким же образом символы представляются и обрабатываются в вычислительных машинах?
Допустим, что алфавит, с которым мы хотели бы иметь дело, включает 256 различных символов - число, явно достаточное для того, чтобы в него вошли все упоминавшиеся символы.
Представим себе, что имеется колода из 256 карт, на каждой из которых напечатан определенный символ нашего алфавита, причем, естественно, каждой карте соответствует свой символ. Сколько вопросов, допускающих ответы "да" и "нет", необходимо задать для того, чтобы при случайном выборе одной карты из колоды можно было определить, какой знак на ней напечатан? Очевидно, решение можно найти, задав самое большее 256 вопросов. Можно каким-то образом упорядочить символы и начать с вопроса, не есть ли это первый символ нашего упорядочения, например "это прописная буква А?". Получив ответ "нет", мы спрашиваем далее, не есть ли это второй символ упорядочения, и так далее.
Если, однако, это упорядочение известно и нам, и тому, кто нам отвечает, то имеется значительно более экономный способ организации опроса. Мы опрашиваем, находится ли отыскиваемый нами символ в первой половине набора. Независимо от ответа выделяем набор из 128 символов, среди которых находится тот, который нам нужен. Мы снова спрашиваем, находится ли искомый символ в первой половине этого меньшего набора, и так далее.
Продолжая действовать таким способом, мы непременно установим, какой символ напечатан на выбранной карте, задав ровно восемь вопросов. Мы смогли бы фиксировать ответы, получаемые на наши вопросы, ставя "1" В тех случаях, когда ответ "да", и "0" - в случае "нет". В таком случае соответствующая запись будет содержать восемь так называемых бит, каждый из которых является либо "1", либо "0". (Говоря о записи числа в десятичной системе счисления, мы рассматриваем числа 0, 1,..., 9 как десятичные цифры. Наша же система записи допускает лишь два символа: "0" и "1"; мы называем их битами.)
Итак, эта восьмибитовая цепочка является однозначным представлением знака, который мы отыскиваем. Более того, каждый из знаков, образующих это множество, обладает некоторым единственным восьмибитовым представлением в одном и том же упорядочении.
На самом деле, существуют общепринятые соглашения относительно упорядочиваний именно таких наборов знаков и их индивидуального кодирования. (То, что эти соглашения признаются не абсолютно всеми, в данном случае нас не интересует, по крайней мере сейчас.)
В последние годы специфические коды, используемые в вычислительных машинах, выпускаемых компанией IBM, заняли положение, очень близкое к общемировому промышленному стандарту. В рамках этого соглашения цепочка из восьми бит, представляющая некоторый знак (алфавита, насчитывающего 256 знаков), называется байтом, а последовательность из четырех байтов - словом.
Мы убедились в том, что всякий текст можно представить некоторой цепочкой единиц и нулей. Чтобы выполнять какую-либо полезную работу с информацией, закодированной в виде цепочек бит, необходимо иметь возможность манипулировать ими некоторым регулярным способом, т. е. играть с ними в какие-то игры. Теперь нам известны "фигуры" игр, играть в которые у нас может возникнуть желание. Единственное, что остается, - это установить правила. Однако прежде, чем заняться этим, позвольте мне сказать несколько слов относительно "электрических" аспектов представления цепочек бит и обращения с ними.
Всегда можно сказать, протекает через некоторый проводник электрический ток или нет. Рассмотрим проводник, соединенный с источником электрической энергии и соответствующим образом подключенным выключателем. Если выключатель включен, то по проводнику течет электрический ток, в противном случае - нет. Предположим, что выключатель связан с каким-то механизмом, который регулярно его включает и выключает; скажем, в течение одной секунды выключатель остается включенным, затем на одну секунду выключается и так далее. В таком случае электрический ток в проводнике можно рассматривать как некоторую последовательность импульсов (рис. 3.1). Обычный дверной электрический звонок - генератор импульсов. Когда к нему поступает энергия, т. е. при нажатии кнопки звонка, выключатель включается. Электрический ток, проходящий через проводник, заставляет молоточек звонка перемещаться, что приводит к выключению выключателя. Затем выключатель снова включается и т. д.
Современная вычислительная машина - это, несомненно, некоторый электрический прибор, точно так же, как им является дверной электрический звонок. Нажимая на кнопку звонка, мы считаем, что звонок "включен", хотя он в каком-то смысле сам включается и выключается в то время, как кнопка остается нажатой. Можно считать, что работающая вычислительная ма-

Рис. 3.1. Последовательность импульсов прямоугольной волны
шина так же включается и, находясь в этом состоянии, включается и выключается последовательностью импульсов типа описанной выше. В этом случае с принципиальной точки зрения время работы вычислительной машины состоит из периодов двух типов: бездействия, когда она в некотором роде "выключена", и активности, на протяжении которого происходит все то, что должно происходить. В сущности, рассмотренная регулярная последовательность импульсов исполняет роль часов. Состояние "отсутствия тока" в проводнике, по которому эта последовательность передается, сигнализирует период бездействия, а наличие тока-активный период.
Для того чтобы понять происходящее внутри вычислительной машины, представим себе полную карту железных дорог какого-нибудь континента, где существующие линии железных дорог представлены проводниками, а каждая железнодорожная станция - парой небольших неоновых лампочек. Взглянув на эту схему, состоящую из проводников и лампочек, в период бездействия, мы заметим, что светятся только некоторые лампочки. В очередной активный период некоторые светившиеся лампочки выключаются, а некоторые темные зажигаются; остальные лампочки находятся в том же состоянии, в котором они были в предшествующий период. Вот и все. Затем наступает очередной период бездействия. В активный период лампочки не мигают. Каждая из них либо сохраняет свое прежнее состояние, либо изменяет его точно один раз, т. е. выключается, если она была включена, или включается, если она была выключена.
Механизм, который мы представили как пару неоновых лампочек, представляет собой электронную схему, состоящую из двух идентичных элементов. Электрический ток может циркулировать по каждому из элементов независимо, т. е. в сущности каждый элемент может независимо нести некоторый импульс. В то же время только один из элементов пары может пропускать ток в любой фиксированный момент. Этот механизм имеет два входных проводника, по одному на каждый элемент. Когда в активный период на элемент, не проводящий в данный момент тока, подается импульс, в этом элементе индуктируется ток, а ток, циркулирующий в другой части механизма, прерывается. Таким образом, этот механизм может переходить из одного состояния в другое и обратно; одна из его "половин" всегда "включена", другая "выключена", причем "половины" постоянно меняются местами. Этот механизм называется триггером. Элементы триггера также снабжены выходящими из них проводниками, каждый из которых, естественно, передает электрический ток, т. е. импульс, во время активного периода, когда соответствующая половина триггера находится в состоянии "включено".
Роль триггера в схеме вычислительной машины заключается в "запоминании" того, на какую из двух его половин в последний раз был подан импульс. Триггер - это устройство для хранения одного бита информации.
Теперь появилась другая возможность объяснить, что именно происходит в вычислительной машине в активный период: большое число триггеров изменяет свое состояние. Однако назначение вычислительной машины состоит в обработке информации, а не просто в передаче ее из одного места в другое. Обработка информации - это, как мы уже установили, в сущности, проблема преобразования. Итак, любой отдельно взятый проводник, ведущий от одного элемента какого-либо триггера к элементу какого-то другого триггера, может за один активный период передать самое большее один импульс. Следовательно, любые преобразования, которые необходимо произвести в один активный период, должны являться результатом выполняемых на "электрическом" уровне операций над строкой импульсов, поступающих параллельно, а не над потоками импульсов, следующих один за другим.
Представим себе колоссальную телефонную сеть, в которой каждый телефон постоянно соединен с другими; у этих телефонов нет диска для набора. Все абоненты смотрят телевизионную программу по одному каналу, и как только начинается передача рекламы, т. е. активный период, они спешат к своим телефонам и сообщают: "единица" или "ноль" - в зависимости от того, что написано на листе блокнота, прикрепленного к аппарату. Они также слышат то, что сообщают им в зависимости от услышанного и записывают в свои блокноты 1 или 0. Один телефон может одновременно быть источником сообщения для нескольких принимающих аппаратов и, кроме того, служить приемником для нескольких передатчиков. Тем не менее сигнал, поступающий в каждый приемник, должен быть однозначной "единицей" или "нулем". Следовательно, необходимы операторы (электронные устройства), расположенные вдоль проводников, связывающих между собой принимающие аппараты, и наделенные функциями формирования единственного сигнала (1 или 0) из потенциального множества входных сигналов.
Такие устройства называются вентильными схемами.
Рассмотрим три разновидности вентильных схем, каждая из которых обладает своей функцией. Простейшей является вентильная схема (рис. 3.2), передающая
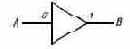
Рис. 3.2. Вентильная схема НЕТ
"единицу" при поступлении на нее "нуля" и наоборот. Это вентиль "НЕТ". Его работа описывается следующими выражениями:
| НЕТ (0) = 1, |
| НЕТ (1)= 0. |
Вентиль имеет один вход А и один выход В. Вентильная схема "И" (рис. 3.3) имеет два входа и один выход. Она передает "единицу" в том и только том случае, если оба ее входа - "единицы"; в противном случае эта схема передает "нуль". Работа вентиля "И" описывается следующими выражениями:
| И (0, 0)=0, |
| И (0, 1)=0, |
| И (1, 0)=0, |
| И (1, 1) = 1. |
Вентильная схема "ИЛИ" (рис. 3.4) также имеет два входа и один выход. Она передает "единицу" всякий раз, когда любой из ее входов или оба входа сразу яв-
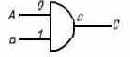 Рис. 3.3. Вентильная схема И |
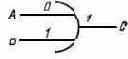 Рис. 3.4. Вентильная схема ИЛИ |
ляются "единицами"; в противном случае она передает "нуль". Работа этой вентильной схемы описывается следующими выражениями:
| ИЛИ (0, 0)=0, | ИЛИ (0, 1) = 1, |
| ИЛИ (1, 0) = 1, | ИЛИ (1, 1) = 1 |
Заинтересованный читатель может проследить прохождение импульсов через систему вентилей (рис. 3.5), представляющую схему, элементами которой служат вентильные схемы "И", "ИЛИ" и "НЕТ", а функцией-арифметическое сложение двух двоичных цифр.
Сложение в двоичной системе счисления аналогично сложению в десятичной системе, но намного проще. Десятичная сумма 2 и 3 равна 5. Десятичная сумма 7 и 8 также равна 5, но имеет место еще "перенос" единицы, которая прибавляется к сумме соседнего слева столбца, какой бы она ни была. В двоичной системе существуют только две цифры: 0 и 1, Правила сложения чрезвычайно просты, а именно:
| 0+0 = 0, |
| 0+1 = 1, |
| 1+0 = 1, |
| 1+1 = 0 и переносится 1. |
Итак, изображенный здесь однобитовый двоичный сумматор имеет три входа: A, В и С и два выхода: S и D.
А и В представляют два бита, которые должны быть сложены, а С - перенос, который мог бы быть порожден аналогичным сумматором, находящимся, так сказать, справа от изображенного здесь. S - полученная сумма, D - перенос.
На самом деле читателю не нужно прослеживать импульсы, проходящие через сумматор. Важно лишь понять, что комбинации, составленные из вентильных
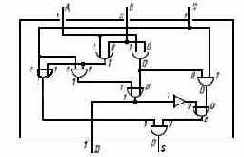
Рис. 3.5. Схема однобитового сумматора;
представлены входные данные и полученный результат
схем трех описанных типов, позволяют реализовать правила трансформации информации. Отметим также, что вся схема помещена в коробку, которая имеет три входа (А, В и С) и два выхода (S и D); эта коробка представляет собой некий блок. Мы объединили простые элементы, чтобы создать более сложный элемент. Теперь можно объединить, скажем, 32 подобных сумматора и сформировать 32-битовый сумматор. Этот сумматор окажется некоторым элементом. И создание, и программирование вычислительных машин - именно такой процесс формирования больших объектов из меньших.
Вернемся снова к нашей воображаемой телефонной сети, но теперь будем считать, что вентильные схемы участвуют в беседах (если это можно так назвать) абонентов между собой. Можно представить себе трех абонентов А, В и С, берущих в нужный момент времени свои телефоны и сообщающих 1, 0 и 0 соответственно. Если они связаны с абонентами S и D представленной выше схемой, то абонент S будет слышать "1", a D - "0", и каждый из них запишет услышанное в своем блокноте.
Конечно, в настоящих вычислительных машинах роль таких "абонентов" выполняют триггеры, а периоды вещания чрезвычайно коротки. Таким образом, в вычислительных машинах результаты вычислений, т. е. преобразований, которым подвергается информация во время активных периодов, хранятся в триггерах. В них они пережидают периоды бездействия, чтобы затем подвергаться дальнейшим преобразованиям в следующие периоды активности.
Мы уже отмечали, что однобитовые сумматоры можно соединять так, чтобы формировать 32-битовый сумматор.
Входами такого сумматора служат два набора по 32 триггера каждый (переносы - внутреннее дело многокаскадного сумматора), выходом также служит набор из 32 триггеров. Можно считать, что каждый из этих наборов в периоды бездействия содержит 32-битовое двоичное число. Каждое, естественно, должно являться упорядоченным множеством, т. е. таким, в котором некоторый бит - первый, другой - второй и так далее. Подобный набор триггеров называется регистром. Он является еще одним примером элемента, полученного в результате объединения более "элементарных" элементов. Можно ли, однако, сказать, что всякий n-битовый регистр содержит n-битовое число? Нет, по крайней мере не при любых обстоятельствах. Дело в том, что интерпретация, которую можно дать строке бит, содержащейся в некотором регистре, зависит от того, какие элементы соединены с этим регистром и, следовательно, какие операции можно осуществлять с его содержимым. Если два регистра соединены лишь с элементами, выполняющими арифметические операции, т. е. если вычислительная машина оперирует с содержащейся в этих регистрах информацией исключительно как с числами, то это числа - по крайней мере до тех пор, пока они обрабатываются в вычислительной машине. Чтобы понять, что символы естественного языка подчиняются аналогичным ограничениям, достаточно вспомнить случаи, когда одно и то же слово выполняет в одной ситуации роль числительного, в другой наречия, а в третьей - неинтерпретированной цепочки знаков [Прим. перев.: В качестве примера указанных ограничений автор приводит английские фразы со словом one - "один" (имя существительное), "один, единственный, какой-то" (имя прилагательное), "этот, тот (самый)" (в грамматическом значении указательного местоимения); отмечается, что это слово в одном случае обозначает число, в другом - некоторое слово, а в третьем является интерпретированной цепочкой знаков]
Действующая вычислительная машина вовлечена в тщательно продуманную и очень сложную игру.
е. состояния восьми его триггеров, и наоборот.
Теперь представим себе комплекс почтовых ящиков в жилом доме, снабженный одним секретным замком. Чтобы достать что-то из определенного почтового ящика или положить в него что-то, в первую очередь необходимо набрать на замке адрес соответствующего ящика. Память вычислительной машины снабжена точно таким же устройством: регистром. (Регистра на 20 бит было бы достаточно для снабжения адресами 1048576 ящиков.) Такой адресный регистр целесообразно рассматривать как часть центрального процессора вычислительной машины, несмотря на то, что он соединен и с памятью вычислительной машины и с ее центральным процессором. Рассмотрение адресного регистра в качестве части центрального процессора помогает, однако, осознать, что его содержимое является объектом машинной обработки. Им могут быть, например, промежуточные результаты какой-либо длинной последовательности арифметических вычислений, и его можно использовать, по сути дела, как порядковые числа.
Наличие адресов у памяти современных вычислительных машин - одно из их наиболее важных свойств. Чтобы оценить колоссальную разницу, которую возможность адресации определяет в одном только способе поиска в памяти, рассмотрим следующую задачу, Пусть в каком-то городке число абонентов телефонной сети составляет несколько меньше 10000. Телефонная книга города содержит перечень всех абонентов, составленный в алфавитном порядке, и, естественно, номера их телефонов. Кроме того, для каждого абонента указан порядковый номер его позиции в книге. Например
1 Аабан Джон 369-6244
.
.
.
1423 Джонс Уильям 369-0043
Мы хотим узнать, являются ли последние четыре цифры номера телефона любого абонента порядковым номером любого другого абонента, чей телефонный номер аналогично соответствует порядковому номеру первого абонента. Если взять, скажем, приведенную запись для Джона, то встречается ли, например, запись 43 Бейкер Макс 369-1423, удовлетворяющая указанным условиям?
Простой способ решения этой задачи состоит в просмотре всех записей, начиная с первой, и выяснении того, составляют ли очередная запись и запись с порядковым номером, соответствующим четырем последним цифрам входящего в состав первого телефонного номера, искомую пару.
Ответ будет "да", если мы обнаружим одну такую пару, и - "нет", если после изучения всего списка мы подобной пары не найдем. Худший из возможных случаев тот, в котором вообще нет пар. В такой ситуации к каждой записи приходится обращаться по крайней мере дважды.
Допустим, что телефонная книга записана на ленте того типа, который требуется для рассмотренных нами машин Тьюринга. При этом нужно следить не только за движением ленты, связанным со счетными функциями, но каждую запись придется просмотреть гораздо больше двух раз. Так, в нашем примере для самой первой записи потребовалось бы посмотреть ее, 6242 записи между ней и записью 6244 и саму запись 6244. В классической машине Тьюринга нельзя было бы просто прокрутить часть ленты, разделяющей соответствующие записи, а пришлось бы реально прочесть и интерпретировать каждую запись. Тот же принцип объясняет крайнее раздражение, которое некоторые люди испытывают, когда им говорят, что они упомянуты в большой книге, не снабженной указателем. Им приходится читать всю книгу.
Пример с телефонной книгой свидетельствует не только о том, что наличие адреса увеличивает эффективность поиска, но и показывает, что при некоторых обстоятельствах оно вообще исключает необходимость поиска. Дело в том, что на вопрос, образует ли конкретный абонент с другим абонентом пару указанного типа, ответ можно получить непосредственно, не прибегая к поиску среди не относящихся к этим абонентам данных. Входит ли, например, мистер Аабан в подобную пару? Чтобы выяснить это, обратимся сразу к абоненту с номером 6244. Если четыре последние цифры номера его телефона "0001", то ответ - "да", в противном случае - "нет". Имея в виду сказанное, обратимся снова к наборам из пяти элементов, определяющим некоторую машину Тьюринга Т и являющимся, следовательно, программой для универсальной машины Тьюринга, имитирующей машину Т. Напомним, что в общем виде такой набор из пяти элементов задается как
(текущее состояние, текущий символ, очередное состояние, очередной символ, направление).
В принципе, машина Тьюринга, находящаяся в некотором состоянии, скажем, 19 и просматривающая некоторый символ, например "1", должна прочесть все введенные в ее программу наборы из пяти элементов, все время задаваясь, так сказать, вопросом, является ли считываемая пятерка (правило) той самой пятеркой, которая применима к состоянию 19. Когда машина обнаруживает пятерку, соответствующую ее текущему состоянию и просматриваемому символу, она перезаписывает этот символ, передвигает ленту и (возможно) изменяет свое состояние. Затем поиск начинается снова. Однако если пятерки хранятся в адресуемой памяти, то поиска подходящей пятерки можно избежать или по крайней мере уменьшить его продолжительность. Допустим, что все пятерки, связанные с некоторым определенным состоянием, требуют, скажем, 100 байт памяти, и начало первой пятерки приходится на регистр 1000. В таком случае набор, соответствующий состоянию 19, будет содержаться в памяти, начиная с регистра с номером 1000+(19-1) x 100, т. е. регистра 2800. Таким образом, понятие состояния полностью переходит в понятие адреса, по крайней мере в данном контексте.
В реальных вычислительных машинах данные также хранятся в адресуемой памяти. Эта рационализация позволяет избавиться и от ограничения, состоящего в том, что немедленный доступ обеспечен лишь к данным, размещенным непосредственно рядом с теми, которые в данный момент просматриваются. Обсуждение использования адресуемости при составлении реальных программ для вычислительных машин начнем с небольшой практической задачи.
Требуется вычислить квадратные корни чисел. (Это означает, что если задано некоторое число, скажем, 25, то требуется определить, какое число, умноженное само на себя, даст заданное. Квадратный корень из 25 равен 5, так как 5 x 5 - 25.) Допустим, что у нас есть добросовестный слуга (человек), без устали исполняющий любую данную ему команду. Известен алгоритм вычисления квадратных корней из положительных чисел. Если задано число n, то его квадратный корень вычисляется следующим образом:
- а) умножения первого варианта приближения самого на себя,
- б) сложения заданного числа n с полученным произведением,
- в) деления полученной суммы на удвоенное значение первого приближения
(Исаак Ньютон доказал, что этот вычислительный процесс всегда приводит к получению лучшего приближения, за исключением, естественно, случая, когда предыдущее приближение уже само являлось точным решением);
Эта процедура обосновывается следующим образом. Допустим, что извлекается квадратный корень из 25 и исходным предположением является, скажем, 4. Нам известно, что эта величина слишком мала, так как 4 x 4=16. Если разделить заданное число, т. е. 25, на значение нашего предположения, то частное будет больше искомого результата, который в данном примере равен 5. Следовательно, значения частного и исходного допущения служат границами искомого результата. Взяв в таком случае среднее из этих двух значений, получим следующее приближение, причем, более того, приближение более точное, чем то, на основе которого оно вычислено. Мы можем итеративно продолжать этот прием до тех пор, пока не получим результат, настолько близкий к правильному, насколько мы этого хотим.
Наш слуга, однако, не гений. Он привык иметь дело с бланками налоговых деклараций, в которых требуется подсчитать что-то и записать результат в такую-то строчку или прямоугольник. Поэтому мы подготовили "рабочий лист", в основе которого лежат указанные процедуры.
Служащий работает в небольшой кабине, снабженной прорезями для приема и выдачи материалов. Как только полоска бумаги с написанным на ней числом появляется во входной прорези, он яростно принимается за работу. Закончив ее, записывает результат на бумаге и подает ее в выходную прорезь.
Единственная начальная команда, которая ему дается, - выполнить команду, содержащуюся в строке 101 рабочего листа, и продолжать выполнять команды в том порядке, как они записаны на листе, до тех пор, пока он не дойдет до содержащейся на листе команды прекратить делать это. Он получит к тому же добрый совет пользоваться для записей только карандашом и иметь хорошую резинку для стирания; он должен использовать то небольшое место на рабочем листе, которое ему предоставлено, чтобы многократно делать соответствующие записи. (Читатель не должен пытаться доводить вычисления в данном примере до победного конца. Может, однако, оказаться полезным довести вычисления до получения двух уточненных приближений значения квадратного корня из 25.) Отметим важную роль, которую играет прямоугольник А. В сущности, это регистр, содержащий промежуточные результаты вычислений. Отметим также, что ни одна команда не содержит обращения более, чем к одному номеру строки. Команды, обладающие этим свойством, называются одноадресными.
Можно выполнять, например, сложения (для чего требуются два операнда), запоминая сначала один операнд в прямоугольнике A, затем прибавляя другой операнд к содержимому прямоугольника А и помещая снова сумму в прямоугольник А. Строки 121, 123 и 124 служат в качестве временных запоминающих регистров.
Указания по извлечению квадратного корня
(Рабочий лист)

Прямоугольник А
И, наконец, обратим внимание на то, что и команды, и: запоминание промежуточных результатов организованы таким образом, что использованный рабочий лист можно использовать снова. При втором и последующих использованиях прямоугольник А и строки 121, 123 и 124 содержат числа, не имеющие отношения к новой задаче. Последние, однако, не будут препятствовать новому циклу вычислений.
Здесь мы следуем почти повсеместно принятой практике программирования. В то время как в большинстве общественных туалетов имеется табличка, призывающая пользующихся ими оставлять туалет после себя в том же виде, какой он имел до использования, мы приняли прямо противоположное правило. Мы говорим: "Приведите рабочее пространство в то состояние, которое вы считаете необходимым для начала настоящей работы".
Мы всегда запоминаем "предыдущее приближение", например в строке 123. После использования рабочего листа эта строка содержит последнее "предыдущее приближение" последнего завершенного цикла вычислений. Новое вычисление, для которого последнее зафиксированное "предыдущее приближение" не имеет абсолютно никакого значения, начинается с переноса "1", нашего стандартного первого приближения, в строку 123 (см. строки 102 и 103).
Вычислительная процедура обсуждаемого нами типа называется стандартной программой, но почему это так, судя по всему, никому не известно. Мы говорим о начале подобного вычислительного процесса, как о входе в программу, завершив же выполнение последнего шага программы, говорим, что выходим из программы. Маленькие стандартные программы типа приведенной здесь редко используются интенсивно и как подпрограммы, и сами по себе. В самом деле, сколько раз может потребоваться знание квадратного корня некоторого числа вне рамок решения какой-то большей вычислительной задачи? Такой задачей может оказаться, например, вычисление корней квадратного уравнения вида ах2+bх+с=0. Искомые корни определяются с помощью следующей формулы:
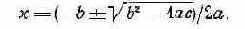
В данном случае задача определения корней квадратного уравнения включает в качестве подзадачи вычисление квадратного корня из некоторого числа. Можно составить рабочий лист, очень похожий на предыдущий, который определит действия человека-вычислителя при решении задачи в целом. Однако, поскольку уже есть рабочий лист, указывающий порядок вычисления квадратных корней, разумнее предложить человеку, решающему большую задачу, использовать готовый рабочий лист при решении соответствующей подзадачи, когда он с ней столкнется, т. е. после вычисления величины (b2-4ас). Таким образом, стандартная программа вычисления квадратного корня становится подпрограммой большей стандартной программы. Естественно, эта большая стандартная программа может снова оказаться подпрограммой еще большей стандартной программы и так далее. Я снова подчеркиваю, что большая часть вычислительных машин и вычислений связаны с построением больших иерархических структур из меньших. Описанная стандартная программа извлечения квадратного корня может выполнять роль подпрограммы некоторой большей процедуры именно потому, что мы позаботились о том, чтобы она сама возвращалась в исходное состояние, т. е. приводила себя перед каждым использованием в надлежащий вид.
Проницательный читатель должен заметить, что я обошел молчанием проблему управления, которая несомненно будет преследовать нас, если наши слуги-вычислители в самом деле столь незатейливы, педантичны и лишены воображения при интерпретации подаваемых им команд, как мы описывали. Мы предположили (и будем настаивать на этом предположении), что служащий знает, как прибавить некоторое число, считанное из определенной строки, к содержимому прямоугольника A, как перенести сумму в прямоугольник A, как определить, больше нуля или нет некоторое число, содержащееся в прямоугольнике A, и так далее, - другими словами, он знает достаточно для того, чтобы интерпретировать и выполнять все команды, содержащиеся в рабочем листе процедуры извлечения корня. Но как проинструктировать кого-то, получившего аналогичную подготовку, но работающего с большими задачами, каким образом заключить "подконтракт" со своими подзадачами?
Можно избежать столкновения с этим вопросом, допустив, что вычислитель знает, как извлекать квадратные корни, так же, как мы допускаем, что ему известно, каким образом следует складывать и вычитать. Следует ли нам, однако, предполагать, что ему уже известно, как определяются корни квадратных уравнений? Если мы продолжим подобные допущения, то дойдем до предположения об отсутствии необходимости в вычислительных машинах вообще. В таком случае мы постулируем, что для составления рабочего листа, соответствующего какой угодно вычислительной процедуре, единственное, что требуется написать: "выполняйте процедуру". Можно считать что люди умеют складывать, вычитать и так далее. Если, однако, мы хотим, чтобы они выполняли более сложные задачи обработки символов, то необходимо описать им соответствующие процедуры в таких категориях, которые они уже понимают. С другой стороны, мы не хотим снова и снова описывать часто используемые процедуры. Каждая стандартная программа - это потенциально подпрограмма какой-то большей стандартной программы. Следовательно, написав однажды какую-то определенную стандартную программу, желательно ввести ее в некую библиотеку подпрограмм, из которой ее можно было бы при необходимости вызывать.
В каждой библиотеке существуют определенные правила заказа книг из книгохранилища: читатель заполняет бланк заказа, передаёт его библиотекарю и так далее. Наш случай, однако, требует несколько иного подхода, отличающегося от того, который практикуется в обычных библиотеках с выдачей книг на дом. Мы хотим, чтобы наши работники не только смотрели на рабочий лист, соответствующий заданной вычислительной задаче, но и выполняли работу. Допустим, повар довел приготовление блюда по какому-то рецепту до определенного состояния, а затем предпочел, чтобы специалист, воспользовавшись ингредиентами, уже приготовленными поваром, выполнил ту часть работы, которой он особенно славится. Повар мог бы отдыхать, пока работает специалист, и вернуться к своему занятию лишь после того, когда он передаст ему свое кулинарное произведение.
Предположим, что таких специалистов много. Каким образом повар передаст управление кухней именно нужному специалисту, как установит, что специалист использует именно необходимые ингредиенты, и где он обнаружит результаты работы специалистов? Вот один из способов выяснить все это.
Повар оставляет все ингредиенты, которые специалист должен использовать, в снабженных последовательной нумерацией шкафчиках: первый - в шкафчике 119, следующий - в 120 и так далее. В следующем после содержащего последний ингредиент шкафчике он оставляет номер помещения, в котором он будет находиться, пока специалист работает. На плите он оставляет номер того шкафчика, в котором находится первый ингредиент. И, наконец, повар нажимает на кнопку звонка, установленного в помещении специалиста, местонахождение которого ему известно.
Специалист прекрасно знает правила повара. Услышав звонок, он направляется на кухню, находит на плите номер шкафчика, содержащего первый ингредиент, и приступает к своим таинствам. Закончив, он оставляет блюдо на плите, звонит в помещение, адрес которого он находит в первом шкафчике, расположенном после шкафчиков, содержащих ингредиенты, и уходит.
Для работы этой системы необходимо лишь, чтобы повар и любой специалист, которого пригласят, знали условия. Повар должен точно знать, сколько ингредиентов требуется приглашенному специалисту (повару не хотелось бы, чтобы кто-нибудь, совершенно лишенный воображения, получил вместе с прочими ингредиентами записку с адресом повара), а также адрес специалиста, которого ему нужно пригласить.
Так же, как к нашему рабочему листу, можно обратиться к фактически идентичным правилам вызова подпрограмм.
Обратимся, например, к следующей части рабочего листа. Этот фрагмент - элемент другой большей стандартной программы. На шаге, к которому мы обращаемся, число, квадратный корень которого требуется найти, находится в прямоугольнике А. Данный элемент стандартной программы вызывает подпрограмму извлечения квадратного корня, обеспечивая в то же время возвращение управления к основной программе.
Замечание. Прямоугольник А выполняет роль склада. Теперь специалисту следует сказать, где он должен начинать искать ингредиенты.
Замечание. Подпрограмма извлечения квадратного корня начинается со строки 98.
Замечание. Эта строка содержит адрес строки, которой специалист должен передать управление после того, как он закончит свою работу.
Замечание. Когда эта команда появляется, значение квадратного корня числа, помещенного в строку 680, находится в прямоугольнике А.
Рабочий лист специалиста приведен выше. Однако придется модифицировать его, чтобы учесть рассматриваемые правила. Исходный рабочий лист предлагает работнику взять число, с которым он будет оперировать, из "входной прорези". Теперь номер строки, содержащей эту информацию, находится в прямоугольнике А. Итак, мы записываем:
Замечание. Этот прием называется косвенной адресацией. Первоначально стандартная программа была подготовлена для работы с некоторым числом, содержащимся в строке 121. Этот способ позволяет обойтись без внесения изменений в стандартную программу.
Замечание. Исполнение команд, заданных строками 98 и 99, не повлияло на содержимое прямоугольника А. Поэтому прямоугольник А содержит теперь "513" - номер строки, вызывающей программы, содержащей адрес, по которому следует осуществить возвращение; в нашем примере в строке 513 содержится "514".
Замечание. Строка 117 представляла собой команду останова, но, как показано ниже, заменим ее. Поскольку все команды являются командами одноадресными, термин "адресная часть" применительно к командам однозначен.
Перепишем теперь строки 116 и 117 следующим образом.
Замечание. Оставляем "блюдо", т. е. квадратный корень заданного числа в прямоугольнике А.
Замечание. Символ "0" в этой строке будет, конечно, заменен, как только будет выполнена команда строки 101; другими словами, замена будет производиться при каждом обращении к данной подпрограмме.
Моя цель заключалась в демонстрации одного из множества возможных способов вызова подпрограммы. Хотя приведенный здесь специфический способ работает, он не столь эффективен, как некоторые другие, и его не следует считать стандартным. Принципиальным является то обстоятельство, что некоторая стандартная программа, однажды написанная, может стать элементом какой-то большей стандартной программы. Эту большую стандартную программу можно снова рассматривать как некоторую подпрограмму еще большей стандартной программы и так далее. Одна из причин важности построения подобных вычислительных (т. е. предназначенных для обработки символов) структур заключается в том, что они освобождают разработчика большей системы высшего уровня от необходимости точно знать, каким образом (с помощью какого алгоритма) стандартная подпрограмма низшего уровня выполняет свои функции. Ему следует знать, как он может ее заполучить, в чем состоят правила ее вызова и какова функциональная связь ее выхода и входа. Таким образом, стандартная подпрограмма - это нечто напоминающее временами довольно сложный юридический документ, скажем, договор об аренде дома: вы заполняете все пробелы, подписываете его и отправляете. Все подписавшие такой документ справедливо считают, что юридические последствия именно таковы, какими они их считают.
Иногда, однако, начинаются неприятности из- за того, что вы полагаетесь на стандартные формы документов, "идея" которых как будто ясна, но текст, набранный мелким шрифтом, у вас не хватило времени прочесть. Ниже я остановлюсь на подобных обстоятельствах подробнее.
Человек, в обязанности которого входит составление различных рабочих листов описанного выше типа, быстро устанет из-за необходимости много писать. Довольно скоро он придумает сокращения. Никакая существенная информация не будет утрачена, если, например, строку
(103. Перенесите содержимое строки 123 в прямоугольник А)
исходного рабочего листа представить в следующем сокращенном виде:
(103. GET 123),
или если строку
(105. Прибавьте содержимое строки 123 к содержимому прямоугольника А и запишите результат в прямоугольник А)
представить в сокращенном виде:
(105. ADD 123)
[Прим. перев.: Как отмечает автор, в качестве сокращений использованы английские глаголы (GET - взять, ADD - прибавить); краткость написания этих глаголов позволяет использовать их в качестве сокращений без изменений. Мы увидим в табл. 3.1, что для обозначения операций используются и сокращения, образованные другими способами (части слов, согласные)]
Подобные сокращения (в сущности, это просто глаголы) можно придумать для всех операций, упоминающихся в исходном рабочем листе, и использовать их для кодирования процедуры в целом, как показано в табл. 3.1.
Процедура, закодированная таким образом, еще может быть прочитана человеком. Однако для нас важнее то, что подобный код превосходно читается вычислительной машиной. Неверно считать, что вычислительная машина не прочтет исходный рабочий лист, написанный по-английски. В конце концов мы убедились в том, что любой текст можно свести к цепочке из нулей и единиц. Но приведенный в табл. 3.1 код, взятый без соответствующего комментария, имеет жесткий формат и, следовательно, легко поддается декодированию. Каждая строка представляет одну команду для вычислительной машины, причем каждая команда состоит из двух частей: операции, подлежащей выполнению, например "ADD", и адреса операнда.
Прямоугольник А больше в явном виде не упоминается. Очевидно, что в прямоугольнике А к моменту, когда в нем возникает необходимость, содержится соответствующий, быть может, не упоминающийся операнд, а результат любой операции, скажем, сумма, полученная при сложении каких-либо чисел, заносится в него. С точки зрения вычислительной машины (противоположной точке зрения человека) этот код все еще чересчур пространен. Операционную часть кода
| 101 | INP121 | Возьмите из "ввода" число и перенесите его в строку 121 |
| 102 | GET 122 | Возьмите начальное приближение |
| 103 | STO123 | Введите его как "предыдущее приближение" в строку 123 |
| 104 | GET 123 | Возьмите "предыдущее приближение" |
| 105 | ADD 123 | Удвойте его |
| 106 | STO 124 | Перенесите "удвоенное предыдущее приближение" в строку 124 |
| 107 | GET 123 | Возьмите "предыдущее приближение" |
| 108 | MPY 123 | Умножьте его на него же |
| 109 | ADD 121 | Прибавьте к результату заданное число |
| 110 | DIV 124 | Разделите результат на "удвоенное предыдущее приближение" |
| 111 | STO 124 | Введите "новое приближение" в строку |
| 112 | SUB 123 | Вычтите "предыдущее приближение" из "нового приближения" |
| 113 | ABS | Возьмите полученный результат с плюсом |
| 114 | SUB 125 | Вычтите из последней величины значение допустимого отклонения |
| 115 | JGZ 118 | Если результат больше нуля, пропустите следующие два шага |
| 116 | OUT 124 | Передайте на "вход" новое приближение |
| 117 | STP | Стоп |
| 118 | GET 124 | Возьмите "новое приближение" |
| 119 | STO 123 | Перенесите его на место, занимаемое "предыдущим приближением" |
| 120 | JMP 105 | Вернитесь к началу "цикла" |
| 121 | 0 | Здесь должно храниться задаваемое число |
| 122 | 1,0 | Здесь должно храниться "первое предыдущее приближение" |
| 123 | 0 | Здесь должно храниться "предыдущее приближение" |
| 124 | 0 | Здесь должно храниться "новое приближение" |
| 125 | 0,001 | Здесь должно храниться значение допустимого отклонения |
команды, например ADD, можно заменить единственным символом размером в один байт. (Напомним, что существует 256 различных символов такого типа.) Единственное ограничение, которое вызывается этим обстоятельством, состоит в том, что нельзя рассчитывать более чем на 256 встречных операций, т. е. таких операций, которые не требуют представления исполнителю дополнительных объяснений. Операции такого рода называются непроизводными.
Продолжая перевод вычислительной процедуры нашего примера в машинный код, допустим, что код размером в один байт для команды ADD имеет вид "00110101". Таким образом, если длина некоторой команды, хранящейся в какой-то конкретной вычислительной машине, составляет четыре байта, т. е. 32 бита, то реальный машинный код для строки 105 рабочего листа будет иметь следующий вид:
00110101000000000000000001111011.
Вся стандартная программа в закодированном виде представляется массивом, состоящим из 25 подобных строк.
Мы проиллюстрировали, каким образом некоторую вычислительную задачу можно представить в виде процедуры, выполняемой людьми, и каким образом можно такую процедуру перевести в некоторую нотацию, которая, хотя и является зашифрованной, легко обрабатывается вычислительной машиной. Мы, однако, немного схитрили. Предписание, которым был снабжен наш верный слуга-вычислитель, предлагало ему выполнять команды, содержащиеся в рабочем листе, в том порядке, в котором они написаны, пока какая-то специальная команда не укажет ему, что следует изменить режим работы. Мы, естественно, предполагаем, что он понимает и знает, каким образом следует выполнять непроизводные операции, вызываемые командами рабочего листа. Но, кроме того, мы безмолвно подразумеваем, что он помнит ту позицию рабочего листа, с которой работает, даже тогда, когда занят выполнением, например, какой-то продолжительной процедуры деления. В действительности, организация в программе потока управляющих команд-это задача совершенно отдельная и отличная от задачи выполнения непроизводных операций.
Итак, в рабочий лист следует ввести еще один прямоугольник Р (для счетчика команд), в котором всегда содержится номер строки (т. е. адрес) выполняемой команды. В таком случае приходится назначать "координатора", его обязанность - сообщать исполнителю, в какой строке он может обнаружить соответствующую команду, т. е. строку, адрес которой хранится в прямоугольнике Р. Когда исполнитель сообщает координатору, что предписанная команда выполнена, тот прибавляет 1 к содержимому прямоугольника Р, фиксирует в нем новое значение счетчика и сообщает исполнителю очередное задание. В результате появления команды, нарушающей естественную последовательность управления, приходится заменять содержимое прямоугольника Р адресом той команды, очередь выполнения которой наступает. Например, в результате выполнения строки
(120. Переходите к работе со строкой 105)
исполнитель переносит число 105 в прямоугольник Р и немедленно приступает к выполнению команды, записанной в строке 105, не сообщая координатору о том, что он кончил выполнение предыдущей команды.
В реальных вычислительных машинах работа разделяется в еще большей степени. Существуют компоненты, обеспечивающие выполнение каждой из встроенных или непроизводных операций, которыми оснащена вычислительная машина. Эти компоненты, хотя и могут совместно использовать отдельные схемы, по существу независимы. Кроме того, имеются компоненты, обеспечивающие доступ к памяти вычислительной машины. Многие вычислительные машины оснащены небольшими специализированными вычислительными устройствами, единственным назначением которых является управление обменом информацией между вычислительной машиной и внешним миром.
Не будем останавливаться на подобных подробностях, поскольку это увело бы слишком далеко от наших главных задач. Я выделяю, однако, идею управления ходом выполнения программы, так как это действительно важная концепция. Обратите внимание на две линии, расположенные сбоку программы (см. табл. 3.1). Они иллюстрируют управление ходом выполнения программы или, иначе говоря, структуру данной программы.
Вообще говоря, интерес к столь маленькой программе определяется тем обстоятельством, что она включает условный переход. Совершает программа в процессе исполнения еще одну итерацию или нет, зависит от результата выполнения команды, содержащейся в строке 115. Если при появлении этой команды прямоугольник А содержит число, большее нуля, то осуществляется еще одна итерация. В противном случае, совершив еше несколько шагов, программа останавливается.
Способность вычислительных машин выполнять команды условного перехода, т. е. изменять последовательность управления в программах в зависимости от результатов тестов, осуществляемых над промежуточными результатами ими же выполненных вычислений, это одно из важнейших свойств вычислительных машин, поскольку всякую эффективную процедуру можно свести всего лишь к последовательности команд (т. е. высказываний типа "делайте это" или "делайте то"), перемежаемых командами условного перехода. Более того, требуются только бинарные команды условного перехода (вида "если то-то и то-то верно, то делайте это; в противном случае делайте то"). Если решение, устанавливающее истинность или ложность того-то и того-то, само предполагает реализацию сложных процедур, то его тоже можно представить с помощью команд и бинарных (предусматривающих два варианта разветвления) команд условного перехода.
Итак, мы сделали довольно точный эскиз, тем не менее всего лишь эскиз того, что представляет собой программа и каким образом вычислительная машина ее выполняет. В процессе обсуждения мы преобразовали очень многословный рабочий лист в весьма компактный код, а затем редуцировали и этот код, переведя его в жесткий формат цепочки бит. По ходу дела мы считали, что ни одно из этих усечений не сопровождалось потерей какой-либо существенной информации. Иначе говоря, цепочка из нулей и единиц, являющаяся конечным продуктом всех преобразований, означает то же самое, что и исходный рабочий лист. Чтобы установить, так ли это, следует выяснить, что означает каждый из них.
Что такое составленный нами рабочий лист? Для неграмотного человека он может означать возможность сделать бумажный самолетик, а для матери, думающей, что его составил ее десятилетний ребенок, он означает, что ребенок - будущий гений. В нашем контексте этот лист - некоторый набор команд. Следовательно, его значение для нас представляет собой определенное действие, выполняемое кем-то, понимающим эти команды, когда он им следует. Значением машинного кода в таком случае должна быть работа вычислительной машины, интерпретировавшей этот код в качестве команд и их выполняющей. Мы уверены в том, что знаем, как будет вести себя человек, выполняющий написанные на рабочем листе команды, поскольку они выражены на языке, понятном и ему, и нам. Что будет делать вычислительная машина, получив приготовленный нами код, полностью зависит от ее конструкции. Последняя определяет значение всякой цепочки из нулей и единиц, заданной вычислительной машине. Если определенная цепочка бит, сформированная нами, должна значить для вычислительной машины то же самое, что рабочий лист для вычислителя-человека, то вычислительная машина должна быть оснащена компонентами, функционально эквивалентными каждой из тех операций, которые мы предлагали выполнить вычислителю-человеку, и каждому из средств, предоставленных нами в его распоряжение.
Я очень тщательно следил за тем, чтобы при этом обсуждении, касающемся исполнителей, координаторов, прямоугольников А и Р и так далее, соответствующие средства и функции были бы аналогичны компонентам и функциям настоящих вычислительных машин. В самом деле, настоящие вычислительные машины действительно располагают прямоугольниками А - регистрами, называемыми накапливающими сумматорами, и прямоугольниками Р - регистрами, называемыми счетчиками команд. Настоящие вычислительные машины действительно хранят команды в последовательно пронумерованных регистрах и они действительно организуют управление примерно описанным способом. Современные вычислительные машины значительно сложнее и в структурном, и в функциональном отношениях, чем мой примитивный эскиз.
Но описанные фундаментальные принципы работы действительно служат отправной точкой для понимания даже современных вычислительных машин.
Говоря о машинах Тьюринга, я утверждал, что язык - это некоторая игра, реализуемая с помощью определенного алфавита и подчиняющаяся некоторому набору правил трансформации, олицетворением которых и является вычислительная машина. Это утверждение справедливо и для современных ЦВМ. Процедуры, как мы убедились, могут быть закодированы цепочками бит, формат которых определяется рядом особенностей конструкции той вычислительной машины, для которой они предназначены. Словарь непроизводных элементов, доступный программисту, определяется операциями, встроенными в вычислительную машину. Например, какая-то конкретная вычислительная машина оснащена встроенной функцией извлечения квадратного корня в качестве одной из ее непроизводных операций. В языке, сопоставленном этой вычислительной машине, будет содержаться код операции, соответствующий этой функции, т. е. глагол, означающий "взять квадратный корень". В языке, определенном какой-то другой вычислительной машиной, у которой "взять квадратный корень" не входит в ее набор непроизводных операций, функцию извлечения квадратного корня можно реализовать только с помощью некоторой подпрограммы, т. е. некоторого глагольного оператора, составленного из более элементарных термов.
Я снова хочу подчеркнуть, что любая вычислительная машина определяет некоторый язык - свой машинный язык. Во всех современных ЭВМ машинные языки основаны на алфавите, который представляет собой множество, состоящее из двух символов - 0 и 1. Словари же и правила трансформации этих языков имеют множество вариаций.
Работают ли в таком случае программисты вычислительных машин на языке машины, для которой они составляют программу? Другими словами, неужели они действительно формируют сложные процедуры на языке длинных цепочек бит? Мы убедились в том, что нетрудно преобразовать выражение (ADD 123) непосредственно в цепочку бит
00110101000000000000000001111011.
Вычислительная машина - это превосходное устройство для обработки символов. Довольно просто сформировать процедуру, преобразующую некоторую программу типа приведенной в табл. 3.1 в соответствующую цепочку бит. В действительности подобные процедуры можно приспособить для выполнения вполне "земных", но часто отнюдь не тривиально простых учетных задач, например, таких, как точное задание распределения памяти.
Программы, выполняющие работу такого рода, т. е. перевод программ, записанных с помощью представленной в табл. 3.1 нотации, на машинный язык, называются ассемблерами. Язык, на котором записана преобразуемая программа, и с которого осуществляется трансляция, называется языком ассемблера.
Людям, естественно, значительно легче читать программы, написанные на языке ассемблера, чем на машинном. Поскольку ассемблеры сами по себе являются довольно сложными программами, их также пишут на языке ассемблера-на том, который они сами транслируют. В этом вовсе нет никакого парадокса. Ассемблер представляет собой некоторую процедурную реализацию точно определенных правил, указывающих, каким образом следует преобразовывать выражения, сформированные на основе какого-то определенного алфавита, в выражения, основанные на много более ограниченном алфавите. Следовательно, ассемблер определяет некоторый язык - свой язык ассемблера. Поскольку ассемблер предназначен для перевода любого допустимого текста, написанного на языке ассемблера, на машинный язык, нет ничего таинственного в его способности транслировать с тем же успехом и текст, являющийся его собственным определением.
Я указывал выше, что программа преобразует вычислительную машину в некоторую другую вычислительную машину. Универсальная вычислительная машина, загруженная, например, только программой извлечения квадратного корня, преобразуется в специализированную вычислительную машину, способную вычислять исключительно квадратные корни. Ассемблер, таким образом, также преобразует ту вычислительную машину, в которую он загружен.
Это преобразование, вызываемое ассемблером, имеет важное следствие: программист, составляющий программу для вычислительной машины, пользуясь исключительно ассемблером, совершенно не должен изучать язык, определяемый самой вычислительной машиной - ее машинный язык. Существенно, что в каком-то смысле он никогда не видит той машины, с которой он в действительности имеет дело; он видит некоторый символьный артефакт, который для него и есть машина, и работает с ним.
Программистам не потребовалось много времени, чтобы осознать следующее: возможности вычислительной машины при обработке символов можно использовать и для трансляции языков еще более "высоких уровней". Обратимся, например, к следующему отрывку текста на языке ассемблера:
GET a
ADD b
STO с
Располагая даже теми минимальными сведениями, которые были изложены ранее, можно понять, что этот отрывок представляет собой закодированное алгебраическое выражение с=а+b.
Очевидно, что чрезвычайно простая процедура обеспечит трансляцию алгебраического выражения в приведенный выше отрывок текста на языке ассемблера. Теперь, не обращая особого внимания на детали, можно сказать, что следующий ниже фрагмент представляет закодированную процедуру извлечения квадратного корня, которой мы уже посвятили так много времени.
Процедура SQRT (n):
Возьмите допустимое отклонение = 0,001;
Возьмите предыдущее приближение = 0;
Возьмите новое приближение = 1;
До тех пор пока |предыдущее приближение - новое приближение| > допустимого отклонения,
делайте:
предыдущее приближение=новое приближение;
новое приближение = (предыдущее приближение ** 2 + n ) / 2 * предыдущее приближение;
Конец;
Результат = новое приближение;
Конец процедуры SQRT.
[Прим. перев.: Название процедуры извлечения корня SQRT - аббревиатура, образованная на основе соответствующего английского термина]
Трансляция этой процедуры на язык ассемблера осуществляется сравнительно просто. В сущности на нескольких предыдущих страницах мы именно этим и занимались.
Значительно труднее, однако, написать процедуру, обеспечивающую трансляцию на язык ассемблера любой программы, записанной на языке, одним из примеров которого служит приведенный выше текст. С первого взгляда может показаться, то эта трудность возникает в связи с явной сложностью данного языка по сравнению с предельной простотой языков ассемблера. Верно, что программа-транслятор должна иметь возможность оперировать с очень большим разнообразием синтаксических форм, многие из которых, особенно при появлении в различных комбинациях, являются источником действительно сложных технических проблем. И все же не эти проблемы вызывают наибольшие затруднения.
Что имеют в виду, когда говорят о предъявленной процедуре как об "образце текста" некоторого языка? Какого языка? Первоочередной и намного более сложной является задача просто построения языка "более высокого уровня". Правила образования и трансформации некоторого языка (так же, как и игра) являются в конечном счете настолько же системой ограничений, запретов, насколько и системой разрешений. Сам факт, что основные строительные элементы, используемые при разработке программ на языке ассемблера, предельно элементарны, обеспечивает программисту колоссальное число степеней свободы. Фактически язык ассемблера для некоторой конкретной машины - это мнемоническая транслитерация [Прим. перев.: Транслитерация - передача текста, написанного с помощью одной алфавитной системы, средствами другой алфавитной системы] ее машинного языка. Следовательно, разработчик языка ассемблера вряд ли сталкивается с проблемами значения. Разработчик же языка более высокого уровня должен определить характер и число степеней свободы, предоставляемых авторам, пишущим программы на этом языке. Каждая степень свободы, используемая автором некоторого выбора, - это в самом прямом смысле узурпация степени свободы программиста, который вынужден использовать результат этого выбора. Рассмотрим очень простой пример: d=a+b*с, где "*"-оператор умножения.
Программист может написать на ассемблере либо
GET а
ADD b
MPY c
STO d
что означает умножение с на сумму а и b и запоминание результата в а, либо
GET b
MPY с
ADD a
STO d
что означает сложение а с произведением b и с и запоминание соответствующей суммы в d. Высказывание на языке более высокого уровня, т.е. d=a+b*с, может иметь только одну интерпретацию, которая должна быть определена особенностями конструкции транслятора, следовательно, разработчиком языка. Естественно, это неэквивалентно утверждению, что экспрессия [Прим. перев.: Экспрессия (лингв.) - выразительно-изобразительные качества речи, отличающие ее от обычной (или стилистически нейтральной) и придающие ей образность и эмоциональную окраску] языка высшего уровня неизбежно ограничена. Язык может, например, допускать две различные интерпретации, представляемые выражениями d=(a+b)*с и d=a+(b*с) соответственно.
Проблема, хотя этот чрезвычайно простой пример лишь едва затрагивает ее, заключается не В том, какие процедуры поддаются представлению на языке высшего уровня (большинство подобных языков на самом деле универсальны в тьюринговском смысле), а в том, какой стиль программирования определяет язык. Эйбрахам Маслоу, психолог, заметил как-то: "Человеку, не имеющему ничего, кроме молотка, весь мир кажется гвоздем". Язык - это тоже своего рода инструмент, и он тоже, в действительности очень сильно, определяет то, каким представляется мир носителю языка.
Программист-одиночка, пишущий программу для решения задачи, сугубо относящейся к его конкретной исследовательской проблеме, мало заботится о том, каким образом его программа могла бы структурировать чье бы то ни было, кроме его собственного, представление о мире. Языки высшего уровня, однако, в двух очень важных отношениях предназначены в чрезвычайно значительной степени для роли языков общественных: для использования очень многими программистами в качестве языков, с помощью которых они программируют свои машины, а также в качестве языков, с помощью которых авторы могут представлять друг другу созданные ими процедуры.
На самом деле успех конкретного языка программирования высшего уровня оценивается в основном, так сказать, тем, насколько он доминирует на рынке, т. е. в какой степени из-за него оказались забытыми конкурирующие способы выражения.
Вся история развития наук о поведении в последнее время показывает, какое глубокое влияние успехи применения математики в физике оказали на дисциплины, достаточно далекие от физики. Множество психологов и социологов десятилетиями обсуждают свои проблемы, пользуясь, например, языком дифференциальных уравнений и статистики. Вначале они могли считать привлекаемые ими исчисления просто удобной системой стенографии для описания тех явлений, с которыми они имели дело. Однако по мере того, как они на основе элементов, заимствованных первоначально из чужеродных сфер, строили все более сложные концептуальные системы, давали им названия и обращались с ними как с элементами еще более развитых систем мышления, эти концептуальные схемы перестали служить исключительно способами описания и превратились подобно молотку Маслоу в детерминанты их мировоззрения. Таким образом, создание массового языка - это серьезная задача, чреватая целым рядом последствий и обремененная, следовательно, исключительно высокой ответственностью. Позже я вернусь еще к этой проблеме.
Сейчас я хотел бы обратить внимание на то, что язык, программирования высшего уровня типа представленного предыдущим фрагментом - это, по существу, формальный язык. Значения написанных на нем выражений определяются, естественно, его правилами трансформации, которые, в свою очередь, реализованы в процедурах, переводящих их на язык ассемблера и в конечном счете на машинный язык. Следовательно, если необходимо указать значение определенной программы, написанной на языке высшего уровня, то придется в конечном счете обратиться к ее представлению на машинном языке и даже к соответствующей вычислительной машине. Ответ будет следующим: "Эта программа значит то, что данная вычислительная машина делает с данным кодом".
Однако практически на такие вопросы подобным образом не отвечают. Дело в том, что транслятор сам является некоторой программой и, следовательно, преобразует вычислительную машину, которая им снабжена, в совершенно другую вычислительную машину, а именно в такую, для которой данный язык является ее машинным языком. Существует, таким образом, не только эквивалентность формальных языков и абстрактных игр, но и эквивалентность формальных языков и вычислительных машин. Иначе говоря, существуют важные сферы рассуждений, в которых исчезают различия между языками и их машинными реализациями.
Чтобы эта мысль не казалась замечанием "чисто" философского характера, имеющим небольшое практическое значение, я должен немедленно отметить, что большинство сегодняшних программистов не только действительно рассматривает используемые ими языки как соответствующие машины (буквально так), но многие, может быть большинство из них, не имеют никакого понятия о машинном языке своей вычислительной машины и о характере и структуре трансляторов, служащих посредниками между ними и их вычислительными машинами. Я говорю это не в осуждение. В конечном счете формальный язык высшего уровня - это некоторая абстрактная машина. Не следует обвинять человека за то, что он пользуется языком или машиной, в большей степени соответствующей его задачам, чем какая-то другая машина, только потому, что первая в каком-то отношении проще. Наше наблюдение, однако, поднимает одну важную проблему: если сегодняшние программисты в основном незнакомы с подробностями структуры используемых ими реальных машин, языков и трансляторов, обрабатывающих составленные ими программы, то им также, в основном, должны быть неизменны аргументы, которые я здесь приводил, и, в частности, аргументы, относящиеся к универсальности вычислительных машин и природе эффективных процедур. Как же тогда эти программисты осознают мощь вычислительной машины?
Их убежденность в том, что вычислительная машина может, так сказать, все, т. е.
их правильное интуитивное представление о том, что доступные им языки в некотором нетривиальном смысле универсальны, проистекает в основном из их представления о возможности запрограммировать любую процедуру, если она им вполне понятна. Последнее основывается на их опыте, подтверждающем богатые возможности подпрограмм и сводимость сложных процессов принятия решений к иерархиям двоичных выборов (предусматривающих разветвление на два варианта).
Подпрограмма - это, как я отмечал, такая программа, для понимания связи входа и выхода которой мы не обязаны понимать, каким образом задаваемые входные данные преобразуются в ней в данные, воспроизводимые на выходе. Программист, сталкиваясь с трудной подзадачей, всегда может рассчитывать для ее решения на существование соответствующей стандартной подпрограммы. Возможно, он обнаружит ее в какой-нибудь библиотеке программ. Но даже если ему не удастся найти подпрограмму, он может заняться этой подзадачей после того, как разработает стратегию решения своей основной задачи. Если, скажем, основная задача - создание программы, позволяющей вычислительной машине играть в шахматы, то несомненно потребуется подпрограмма выбора хода при заданных расположении фигур на доске и указании, кому ходить - белым или черным. Входом подобной подпрограммы должно являться некоторое представление положения фигур на шахматной доске и, скажем, "0" (при ходе белых) или "1" (при ходе черных). Выходом этой подпрограммы будет конфигурация фигур, воспроизведенная с помощью того же представления, что и входная конфигурация. После того как программист выбрал подходящие представления, что может оказаться также нетривиальной задачей, он вполне может "пользоваться" подпрограммой порождения хода в процессе дальнейшей разработки основной программы так, как если бы указанная подпрограмма уже существовала. Если он - член какой-то группы программистов, то вполне может описать искомую взаимосвязь входа и выхода подпрограммы своему коллеге, который затем эту подпрограмму и напишет.
В любом случае он может продолжить свой стратегический анализ и даже программирование основной задачи, не держа постоянно в голове подробности, относящиеся к низшим уровням.
Я уже отмечал, что и вычислительные машины и вычислительные процессы конструируются по принципу: большие объекты - из меньших. Подпрограммы дают в некотором смысле возможность с тем же успехом утверждать обратное. Дело в том, что с их помощью очень большие и сложные задачи можно разбивать на меньшие, каждую из них на еще меньшие и так далее. Иначе никто не решился бы взяться за решение столь грандиозных задач, как организация управления воздушным движением с помощью вычислительных машин или моделирование на вычислительной машине деятельности крупных предприятий. Конечно, далеко не нова идея решения задачи посредством разделения ее на меньшие и решения последних разделением и так далее. До пришествия вычислительных машин, однако, гигантские иерархические системы решения задач должны были полагаться на людей, реализующих планы генеральных стратегов. Люди же, в отличие от вычислительных машин, не вполне надежные исполнители даже наиболее точных инструкций.
Ощущение могущества, которое испытывает программист ЭВМ, порождается главным образом его уверенностью в том, что его команды будут безусловно выполнены, а его способность создавать произвольно большие программные структуры снимает ограничения по крайней мере с размера тех задач, которые он может решать.
Наконец, я могу истолковать то ошибочное впечатление, которое, несомненно, вызвало одно место в начале гл. 2: "Машины делают только то, для чего они предназначены, и делают они это точно". Теперь нам известно, каким образом можно проинструктировать машину для выполнения различных операций. Если отнестись серьезно к утверждению, что программа преобразует одну вычислительную машину в другую, то теперь понятно, каким образом можно "заставить" машину сделать что-то. Однако может создаться впечатление, что программы обязательно имеют вид (иногда несколько замаскированный) последовательности команд, которые должны выполняться более или менее последовательно.
Я уже приводил противоположные свидетельства. Наборы из пяти элементов, определяющие поведение классической машины Тьюринга, не должны ни иметь какого-то специфического упорядочения, ни выполняться последовательно. Типичные пять элементов такого рода, представленные в форме правила некоторой игры, выглядят так: "Если вы находитесь в состоянии u и символ, который вы в данный момент считываете, - х, то поступайте следующим образом ... ".
Машина Тьюринга буквально ищет на своей ленте правило, применимое к текущей ситуации. Порядок, в котором эти правила записаны, не имеет никакого отношения к результирующим характеристикам "вход - выход" машины.
В этой связи следует сделать два важных замечания. Первое относится к идее поиска правила. Машина Тьюринга осуществляет линейный поиск применимого правила. Информация на ее ленте размещена в линейном порядке. Однако на современных вычислительных машинах реализуются и иные режимы поиска. Можно, в частности, написать программы, предназначенные для "вычисления" правил поиска. Следовательно, точно так же, как программист может знать процедуру вычисления квадратных корней чисел и не знать значения квадратного корня некоторого конкретного числа, не говоря уже обо всех числах, которые можно ввести в его процедуру, он может знать, каким образом задается конструкция правила поиска, но не знать ни одного из тех правил, которые соответствующая конструкция может порождать. Вычислительная машина, следующая правилам, которые она отыскала, реализовав вычисленный указанным образом режим поиска, действительно делает только то, что ей было предписано делать. Это "предписывание", однако, является по крайней мере одним (возможно, и много большим числом) шагом, уводящим от первоначального "предписывателя", т. е. программиста. Ниже я вернусь к значению этого обстоятельства.
Второе замечание связано с тем, каким образом правила, отдаленно напоминающие пять элементов машины Тьюринга, можно задавать вычислительной машине.
Очевидно, что правила можно ввести в виде программ приведенного выше вида. Оставим на время вычислительные машины и посмотрим, как человек попытается ответить на вопрос: "Чему равна площадь блюда?". В первую очередь он предположит, что блюдо, о котором его спрашивают,-последнее упоминавшееся блюдо. Поэтому он начнет искать в своей памяти последнее упоминание о блюде. Если упоминание имело вид: "Площадь блюда такая-то", он сможет быстро ответить на вопрос. В противном случае он начнет искать в своей памяти утверждения вида "площадь того-то и того-то равна...", т. е. какие-нибудь хранящиеся в ней сведения о том, как отвечают на вопросы о площади чего бы то ни было. Допустим, он находит утверждение: "Площадь круга равна квадрату радиуса круга, взятому пи раз". Он может подумать: "Если у блюда есть радиус, оно может иметь форму круга и тогда можно применить это правило". Если окажется, что последнее упоминание о блюде "радиус блюда равен 10", то дальнейшее очевидно. Ниже приведен текст записи "беседы" с вычислительной машиной, проведенной с помощью пульта управления, оборудованного электрической пишущей машинкой (строки, напечатанные только прописными буквами, являются ответами вычислительной машины) 1 [Прим. перев.: Мы приводим здесь перевод этого текста, поскольку он сохраняет смысл реплик и тем самым познавательную ценность данного примера].
Площадь круга равна квадрату его радиуса, умноженному на пи.
Площадь шара равна квадрату его диаметра, умноженному на пи.
Площадь квадрата равна длине его стороны в квадрате.
Диаметр некоторого объекта равен удвоенному радиусу этого объекта.
Радиус мяча равен 10. Чему равна площадь поверхности мяча?
ДОПУЩЕНИЕ О ТОМ, ЧТО МЯЧ - ЭТО КРУГ, ЛОГИЧНО;
СЛЕДУЕТ ЛИ МНЕ ПРОДОЛЖАТЬ?
Нет.
ДОПУЩЕНИЕ О ТОМ, ЧТО МЯЧ - ЭТО И ШАР, И ОБЪЕКТ, ЛОГИЧЕСКИ НЕПРОТИВОРЕЧИВО; СЛЕДУЕТ ЛИ МНЕ ПРОДОЛЖАТЬ?
Да.
ПЛОЩАДЬ ПОВЕРХНОСТИ МЯЧА РАВНА 1256,6359.
Чему равен диаметр мяча?
ОН РАВЕН 20.
Радиус блюда равен 10.
Чему равна площадь блюда?
ДОПУЩЕНИЕ О ТОМ, ЧТО БЛЮДО - КРУГ, ЛОГИЧЕСКИ НЕПРОТИВОРЕЧИВО; СЛЕДУЕТ ЛИ МНЕ ПРОДОЛЖАТЬ?
Да.
ПЛОЩАДЬ БЛЮДА РАВНА 314,15899.
Радиус глобуса равен 10.
Глобус - это шар.
Шар - это объект.
Чему равна площадь поверхности глобуса?
ОНА РАВНА 1256,6359.
Длина стороны тарелки равна 10.
Чему равна площадь тарелки?
ДОПУЩЕНИЕ О ТОМ, ЧТО ТАРЕЛКА - КВАДРАТ, ЛОГИЧЕСКИ НЕПРОТИВОРЕЧИВО; СЛЕДУЕТ ЛИ МНЕ ПРОДОЛЖАТЬ?
Да.
ПЛОЩАДЬ ТАРЕЛКИ РАВНА 100.
Когда я говорю "прибор", я имею в виду тарелку.
Чему равна утроенная длина стороны прибора?
ОНА РАВНА 30.
Пожалуйста, назовите ее "х".
Пусть f(x) равняется "x" в квадрате минус "х".
Вычислите значение f(x).
ОНО РАВНО 870.
Программу, побуждающую вычислительную машину выполнять эти действия, лучше рассматривать не как набор команд вида "если так, то делай так", а как совокупность приемов установления фактов. Эти правила используются для того, чтобы установить, каким образом утверждения, которые можно вводить в машину, соотносятся с теми вопросами, которые ей могут быть заданы. Следовательно, поведение вычислительной машины определяется задаваемыми ей утверждениями (например, "глобус - это шар") в той же мере, что и ее командами.
Часто повторяемый трюизм, что вычислительная машина может делать только то, что ей сказано делать, оказывается, таким образом, подобно большинству трюизмов, касающихся сложных вопросов, по меньшей мере, проблематичным. Существует много способов "сказать" что-то вычислительной машине.
Столь же проблематична идея о том, что можно написать программу, реализующую все, что вы "полностью понимаете". Понимать что-то всегда - значит понимать это на некотором определенном уровне. Актуарий [Прим. перев.: Актуарий - специалист-статистик, работающий в области страхования] использует довольно сложные математические средства, обоснования которых он почти наверняка не понимает или они его совершенно не интересуют.
Всякий, разменивающий деньги, использует арифметику, но лишь очень немногие знают или интересуются великолепной системой аксиом, положенной в основу арифметики. В сущности, все мы постоянно пользуемся подпрограммами, соотношение входа и выхода которых мы считаем известным, а детали их устройства нас не интересуют и мы редко о них задумываемся. Понимать что-то достаточно хорошо, чтобы быть в состоянии составить соответствующую программу для вычислительной машины, не значит понимать проблему глубоко. В практической деятельности невозможно добиться исчерпывающего понимания. Программирование является скорее неким тестом на понимание. Оно напоминает в этом отношении письменное изложение; часто, когда мы считаем, что понимаем какую-то проблему и пытаемся описать ее, сам процесс написания обнаруживает недостаточность этого понимания даже перед нами самими. Наше перо выписывает слова "потому что" и неожиданно замирает. Мы думали, что понимаем "причину" какой-то проблемы, но обнаружили, что не понимаем ее. Мы начинаем предложение с "очевидно" и убеждаемся в том, что то, что мы собирались написать, совсем не очевидно. Иногда мы соединяем две части предложения словом "следовательно", но затем видим, что цепь наших рассуждений ошибочна. В программировании дело обстоит подобным же образом. В конечном счете, программирование - это тоже письменное изложение. Но дело в том, что в ординарном случае, излагая свои мысли на бумаге, мы иногда скрываем недостаточность понимания и логические несообразности, неосознанно используя безмерную гибкость естественного языка и его неотъемлемую неоднозначность. Именно это обилие выразительных средств естественного языка позволяет иногда расцвечивать речь и создает впечатление (естественно, ложное), что оно способно столь же блестяще представлять нашу недостойную логику.
Вычислительная машина, интерпретатор написанных на языках программирования текстов, обладает иммунитетом к соблазнам чистой риторики. Слов же типа "очевидно" нет в словарях непроизводных элементов любой вычислительной машины.
Вычислительная машина - безжалостный критик. Поэтому утверждение о том, что вы понимаете проблему достаточно хорошо для ее запрограммирования, является прежде всего утверждением о том, что вы понимаете эту проблему применительно к очень конкретным обстоятельствам. Во всяком случае, это может оказаться просто хвастовством, которое легко разоблачить эмпирически.
Обратная сторона медали - уверенность в том, что невозможно запрограммировать проблему, если вы не понимаете ее как следует. При этом игнорируется тот факт, что программирование аналогично любой форме письменного изложения: это, скорее, эмпирическая, чем не эмпирическая деятельность. Вы программируете так же, как пишете, не потому, что понимаете, но для того, чтобы понять. Создание программы - творческий акт. Написать программу - значит обнародовать законы для мира, который вы сначала должны создать в своем воображении. И очень редко творец, кто бы они ни был - архитектор, романист или кто-то еще, обладает столь связной картиной мира, возникающего в его воображении, что ему удается создать законы этого мира, избежав критики с его стороны. Именно ее и может обеспечить вычислительная машина.
Критикой, естественно, следует уметь пользоваться. Во многих случаях "критика" ЭВМ имеет очень резкий характер и ее нельзя игнорировать: программа вообще не работает или выдает явно неправильные результаты. В таком случае ясно, что что-то необходимо изменить. Вычислительные машины весьма эффективны в обнаружении чисто технических, т. е. лингвистических, программистских, ошибок, но испытывают затруднения там, где нужно выявить скрытую причину неприятностей, например, установить, какая именно скобка поставлена неправильно. В самом деле, многие программисты считают свое ремесло трудным из-за того, что им приходится иметь дело с языками, обладающими жесткими синтаксическими правилами. Поэтому раздаются настойчивые требования создать системы программирования на естественном, например английском языке. Программисты, придерживающиеся такой точки зрения, вероятно, никогда не имели дела с действительно трудной задачей и.
следовательно, не испытывали потребности в самой серьезной критике со стороны вычислительной машины. Верно, что прежде, чем начинать писать, следует сначала выучить синтаксические правила выбранного языка. Кроме того, нужно тщательно продумать то, что вы собираетесь выразить. Литературная критика не сводится к выискиванию ошибок произношения и технических нарушений правил грамматики, ее задача - решение более существенных проблем. Литературный критик должен много знать.
Истинная причина чрезвычайной трудности программирования заключается в том, что во многих случаях вычислительной машине ничего не известно о тех аспектах реального мира, с которыми ее программа должна иметь дело. Она находится в положении, скажем, учителя английского языка, которого снабдили наставлением для пилота самолета и оставили одного за рычагами управления самолета посреди чистого неба. Он может иметь очень высокую квалификацию специалиста в области грамматики, но о том, как пилотировать самолет, не знать ничего. Поэтому наставление лучше составить в терминах, достаточно элементарных для того, чтобы даже не имеющий никакого отношения к авиации школьный учитель смог бы его понять. Хотя намного легче было бы писать наставление пилоту, рассчитанное на специалиста в области аэродинамики, который тоже не умеет пилотировать самолет, но знает теорию полета. Очень сложно на самом деле объяснить что-нибудь в терминах словаря непроизводных элементов, не имеющего ничего общего с тем, что должно быть объяснено. Тем не менее большинство программ составляется именно так. Возникающие трудности связаны с синтаксической жесткостью не в большей степени, чем, например, трудность написания хорошего сонета сопряжена с твердостью формы, предписываемой этой стихотворной формой. Чтобы написать хороший сонет или хорошую программу, необходимо знать, что вы хотите сказать. При этом полезно, чтобы у критика и у вас была общая база знаний по соответствующей проблеме.
Мы познакомились с программой, частично состоящей из утверждений, заданных на естественном языке.
Их можно сообщать программе в разное время, и набор утверждений может, следовательно, разрастись до очень больших размеров. В таком стиле в определенном смысле программировать проще, чем в обычно используемой более ортодоксальной манере. С помощью подобных методов программирования можно встраивать в вычислительную машину базу знаний. Такая система программирования показывает, что можно обойти жесткость формы, сопутствующую обычно программированию.
Не следует, однако, слишком полагаться на это. Перечень основных физических формул поможет нерадивому студенту решить массу задач из учебника по физике, но не даст ему тем не менее понимания физики-теории, которую он смог бы осмысливать. Точно так же набор утверждений типа приведенных нами позволит вычислительной машине решать некоторые задачи. Это, однако, никоим образом не свидетельствует о владении программистом или вычислительной машиной теорией или понимании ими чего-нибудь, выходящего за пределы способа использования набора "фактов", приводящего к получению определенных выводов. Правильная работа вычислительной машины часто рассматривается как свидетельство понимания ею или человеком, составившим для нее программу, теории, положенной в основу работы вычислительной машины. Подобное заключение не является само собой разумеющимся и чаще оказывается совершенно ошибочным. Связь между пониманием и написанием остается для программирования такой же проблематичной, какой она всегда была для любой иной формы письменного изложения.
